
这是一个创建于 1813 天前的主题,其中的信息可能已经有所发展或是发生改变。
这篇文章不会涉及到 Kafka 的具体操作,而是告诉你 Kafka 是什么,以及它能在爬虫开发中扮演什么重要角色。
一个简单的需求
假设我们需要写一个微博爬虫,老板给的需求如下:
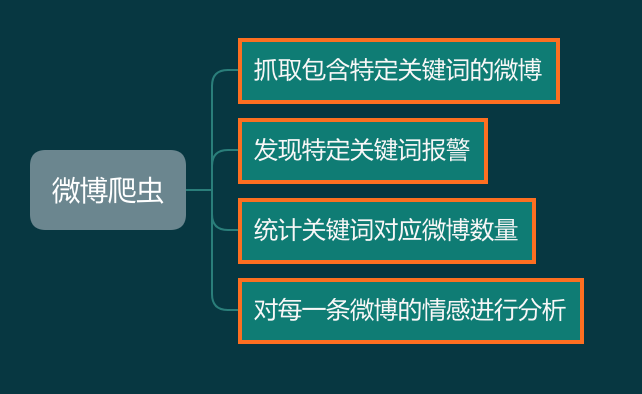
开发爬虫对你来说非常简单,于是三下五除二你就把爬虫开发好了:
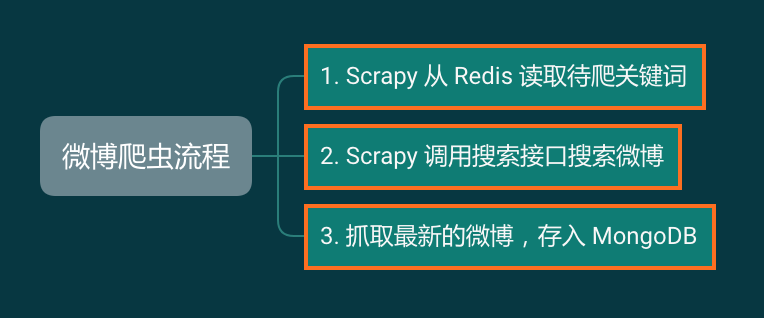
接下来开始做报警功能,逻辑也非常简单:

再来看看统计关键词的功能,这个功能背后有一个网页,会实时显示抓取数据量的变化情况,可以显示每分钟、每小时的某个关键词的抓取量。
这个功能对你来说也挺简单,于是你实现了如下逻辑:

最后一个需求,对微博数据进行情感分析。情感分析的模块有别的部门同事开发,你要做的就是每个小时拉取一批数据,发送到接口,获取返回,然后存入后端需要的数据库:
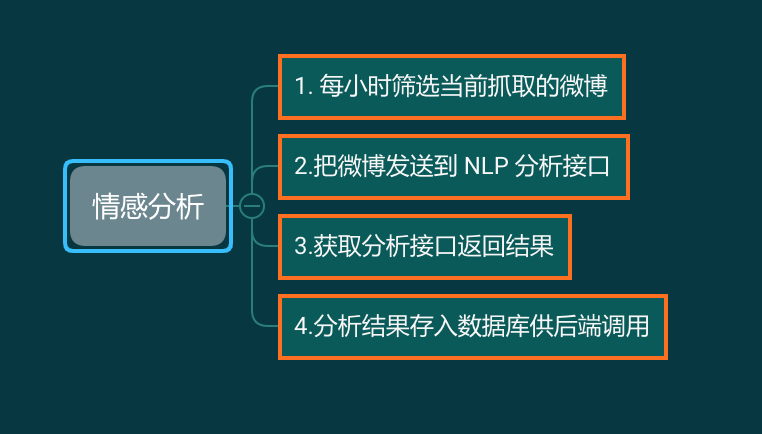
任务完成,于是你高兴地回家睡觉了。
困难接踵而至
爬虫变慢了
随着老板逐渐增加新的关键词,你发现每一次完整抓取的时间越来越长,一开始是 2 分钟抓取一轮,后来变成 10 分钟一轮,然后变成 30 分钟一轮,接下来变成 1 小时才能抓取一轮。随着延迟越来越高,你的报警越来越不准确,微博都发出来一小时了,你的报警还没有发出来,因为那一条微博还没有来得及入库。
你的爬虫技术非常好,能绕过所有反爬虫机制,你有无限个代理 IP,于是你轻轻松松就把爬虫提高到了每秒一百万并发。现在只需要 1 分钟你就能完成全部数据的抓取。这下没问题了吧。
可是报警还是没有发出来。这是怎么回事?
数据库撑不住了
经过排查,你发现了问题。数据抓取量上来了,但是 MongoDB 却无法同时接收那么多的数据写入。数据写入速度远远小于爬取数据,大量的数据堆积在内存中。于是你的服务器爆炸了。
你紧急搭建了 100 个数据库并编号 0-99,对于抓取到的微博,先把每一条微博的 ID 对 100 求余数,然后把数据存入余数对应的 MongoDB 中。每一台 MongoDB 的压力下降到了原来的 1%。数据终于可以即时存进数据库里面了。
可是报警还是没有发出来,不仅如此,现在实时抓取量统计功能也不能用了,还有什么问题?
查询来不及了
现在报警程序要遍历 100 个数据库最近 5 分钟里面的每一条数据,确认是否有需要报警的内容。但是这个遍历过程就远远超过 5 分钟。
时间错开了
由于微博的综合搜索功能不是按照时间排序的,那么就会出现这样一种情况,早上 10:01 发的微博,你在 12:02 的时候才抓到。
不论你是在报警的时候筛选数据,还是筛选数据推送给 NLP 分析接口,如果你是以微博的发布时间来搜索,那么这一条都会被你直接漏掉——当你在 10:05 的时候检索 10:00-10:05 这 5 分钟发表的微博,由于这一条微博没有抓到,你自然搜索不到。
当你 12:05 开始检索 12:00-12:05 的数据时,你搜索的是发布时间为 12:00-12:05 的数据,于是 10:01 这条数据虽然是在 12:02 抓到的,但你也无法筛选出来。
那么是不是可以用抓取时间来搜索呢?例如 10:05 开始检索在 10:00-10:05 抓取到的数据,无论它的发布时间是多少,都检索出来。
这样做确实可以保证不漏掉数据,但这样做的代价是你必需保存、检索非常非常多的数据。例如每次抓取,只要发布时间是最近 10 小时的,都要保存下来。于是报警程序在检索数据时,就需要检索这 5 分钟入库的,实际上发布时间在 10 小时内的全部数据。
什么,你说每次保存之前检查一下这条微博是否已经存在,如果存在就不保存?别忘了批量写入时间都不够了,你还准备分一些时间去查询?
脏数据来了
老板突然来跟你说,关键词“篮球”里面有大量的关于 蔡徐坤的内容,所以要你把所有包含蔡徐坤的数据全部删掉。
那么,这个过滤逻辑放在哪里?放在爬虫的 pipelines.py 里面吗?那你要重新部署所有爬虫。今天是过滤蔡徐坤,明天是过滤范层层,后天是过滤王一博,每天增加关键词,你每天都得重新部署爬虫?
那你把关键词放在 Redis 或者 MongoDB 里面,每次插入数据前,读取所有关键词,看微博里面不包含再存。
还是那个问题,插入时间本来就不够了,你还要查数据库?
好,关键词过滤不放在爬虫里面了。你写了一个脚本,每分钟检查一次 MongoDB 新增的数据,如果发现包含 不需要的关键词,就把他删除。
现在问题来了,删除数据的程序每分钟检查一次,报警程序每 5 分钟检查一次。中间必定存在某些数据,还没有来得及删除,报警程序就报警了,老板收到报警来看数据,而你的删除程序又在这时把这个脏数据删了。
这下好了,天天报假警,狼来了的故事重演了。
5 个问题 1 个救星
如果你在爬虫开发的过程中遇到过上面的诸多问题,那么,你就应该试一试使用 Kafka。一次性解决上面的所有问题。
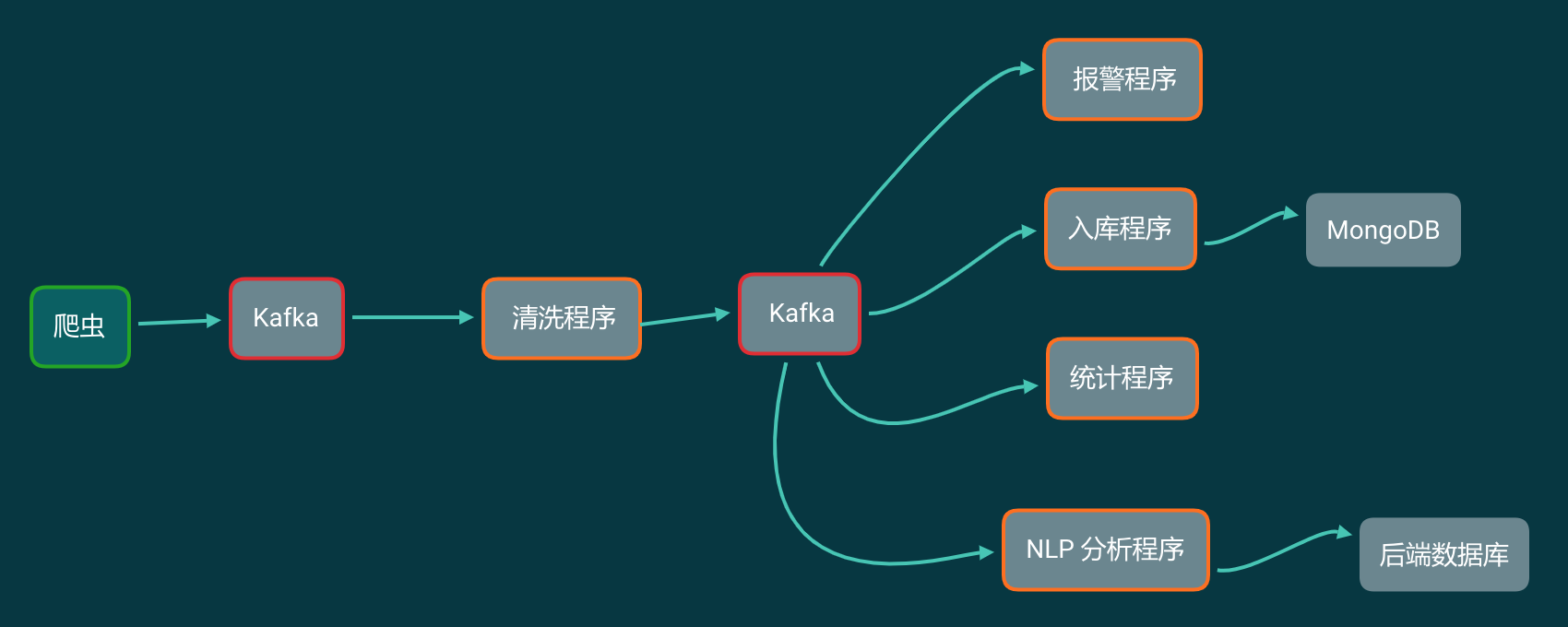
把 Kafka 加入到你的爬虫流程中,那么你的爬虫架构变成了下面这样:
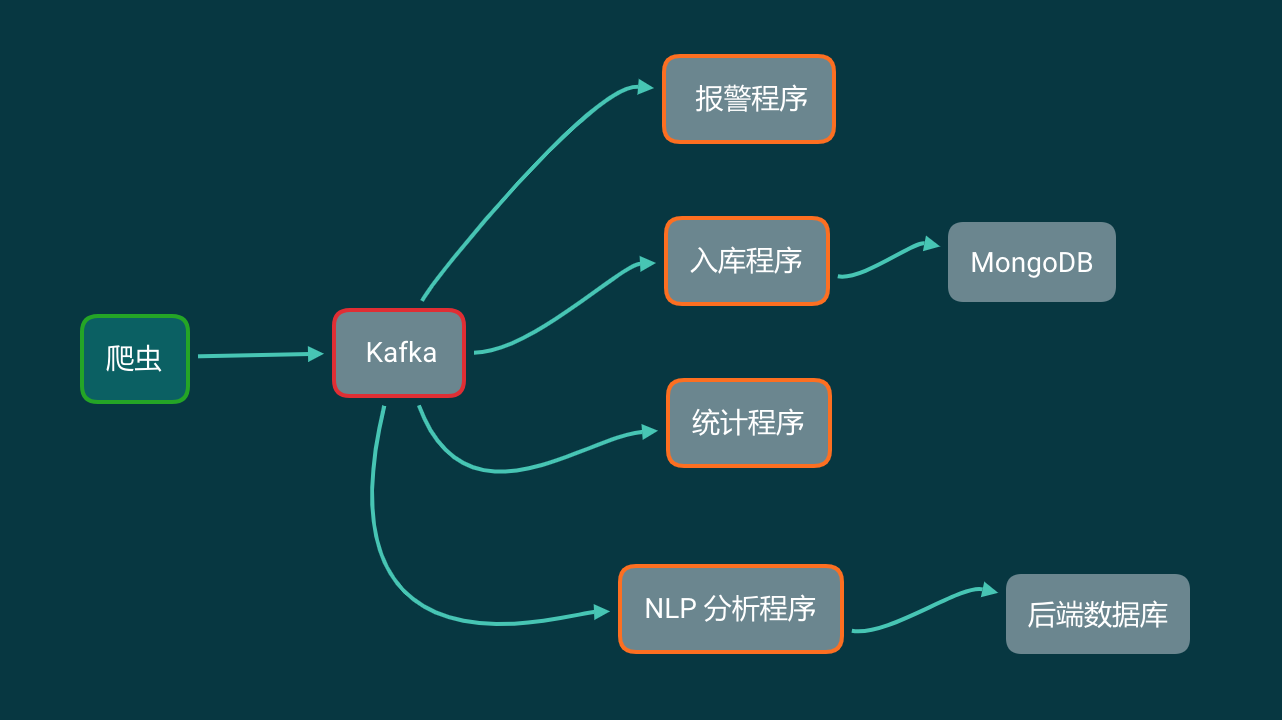
这看起来似乎和数据直接写进 MongoDB 里面,然后各个程序读取 MongoDB 没什么区别啊?那 Kafka 能解决什么问题?
我们来看看,在这个爬虫架构里面,我们将会用到的 Kafka 的特性:
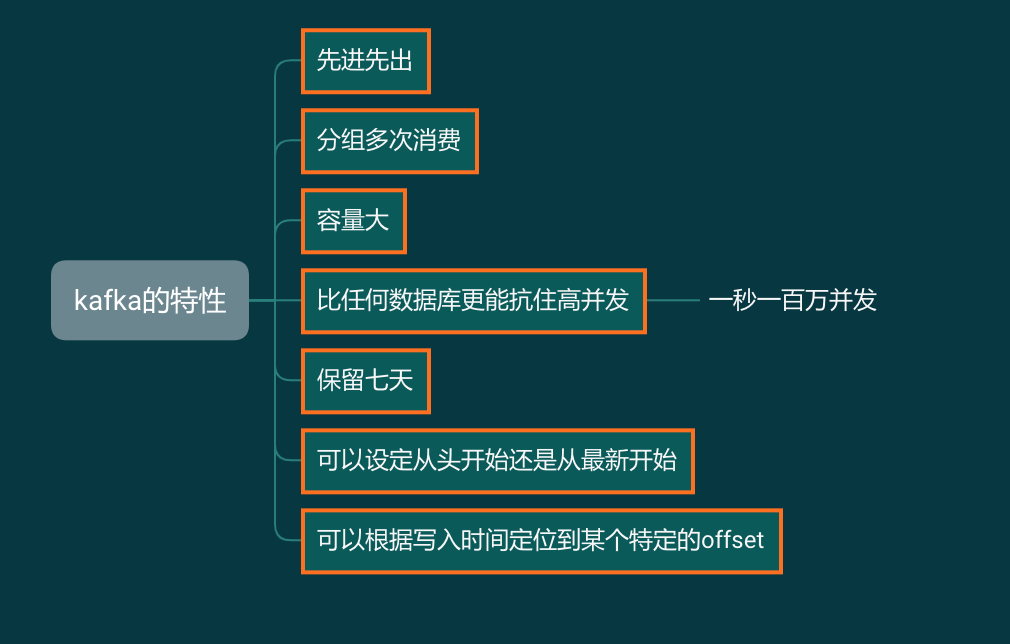
与其说 Kafka 在这个爬虫架构中像 MongoDB,不如说更像 Redis 的列表。
现在来简化一下我们的模型,如果现在爬虫只有一个需求,就是搜索,然后报警。那么我们可以这样设计:
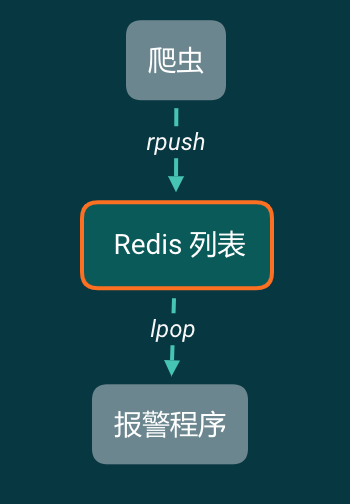
爬虫爬下来的数据,直接塞进 Redis 的列表右侧。报警程序从 Redis 列表左侧一条一条读取。读取一条检视一条,如果包含报警关键词,就报警。然后读取下一条。
这样做有什么好处?
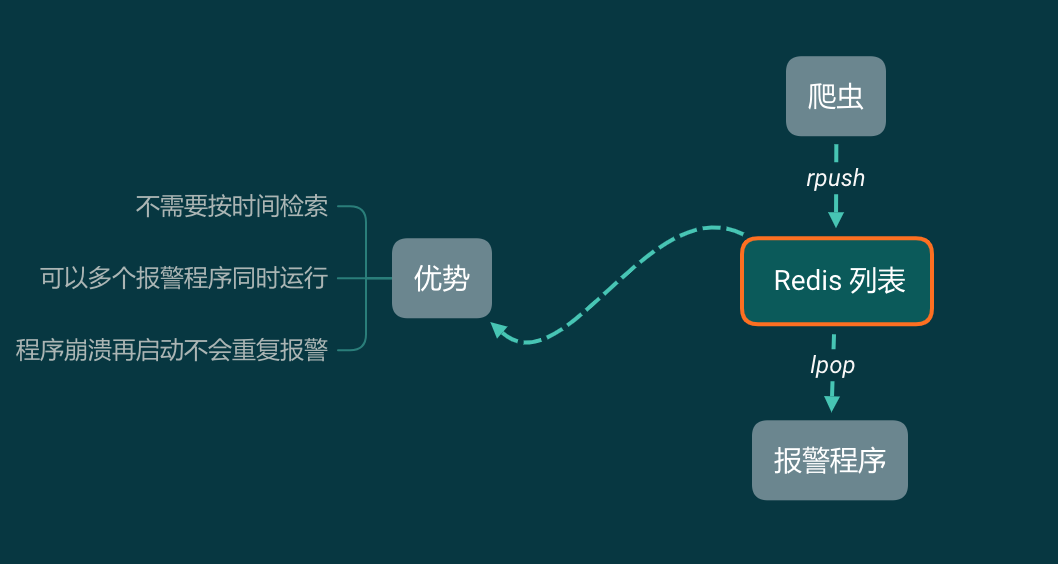
因为报警程序直接从 Redis 里面一条一条读取,不存在按时间搜索数据的过程,所以不会有数据延迟的问题。由于 Redis 是单线程数据库,所以可以同时启动很多个报警程序。由于 lpop 读取一条就删除一条,如果报警程序因为某种原因崩溃了,再把它启动起来即可,它会接着工作,不会重复报警。
但使用 Redis 列表的优势也是劣势:列表中的信息只能消费 1 次,被弹出了就没有了。
所以如果既需要报警,还需要把数据存入 MongoDB 备份,那么只有一个办法,就是报警程序检查完数据以后,把数据存入 MongoDB。
可我只是一个哨兵,为什么要让我做后勤兵的工作?
一个报警程序,让它做报警的事情就好了,它不应该做储存数据的事情。
而使用 Kafka,它有 Redis 列表的这些好处,但又没有 Redis 列表的弊端!
我们完全可以分别实现 4 个程序,不同程序之间消费数据的快慢互不影响。但同一个程序,无论是关闭再打开,还是同时运行多次,都不会重复消费。
程序 1:报警
从 Kafka 中一条一条读取数据,做报警相关的工作。程序 1 可以同时启动多个。关了再重新打开也不会重复消费。
程序 2:储存原始数据
这个程序从 Kafka 中一条一条读取数据,每凑够 1000 条就批量写入到 MongoDB 中。这个程序不要求实时储存数据,有延迟也没关系。 存入 MongoDB 中也只是原始数据存档。一般情况下不会再从 MongoDB 里面读取出来。
程序 3:统计
从 Kafka 中读取数据,记录关键词、发布时间。按小时和分钟分别对每个关键词的微博计数。最后把计数结果保存下来。
程序 4:情感分析
从 Kafka 中读取每一条数据,凑够一批发送给 NLP 分析接口。拿到结果存入后端数据库中。
如果要清洗数据怎么办
4 个需求都解决了,那么如果还是需要你首先移除脏数据,再分析怎么办呢?实际上非常简单,你加一个 Kafka ( Topic ) 就好了!
大批量通用爬虫
除了上面的微博例子以外,我们再来看看在开发通用爬虫的时候,如何应用 Kafka。
在任何时候,无论是 XPath 提取数据还是解析网站返回的 JSON,都不是爬虫开发的主要工作。爬虫开发的主要工作一直是爬虫的调度和反爬虫的开发。
我们现在写 Scrapy 的时候,处理反爬虫的逻辑和提取数据的逻辑都是写在一个爬虫项目中的,那么在开发的时候实际上很难实现多人协作。
现在我们把网站内容的爬虫和数据提取分开,实现下面这样一个爬虫架构:
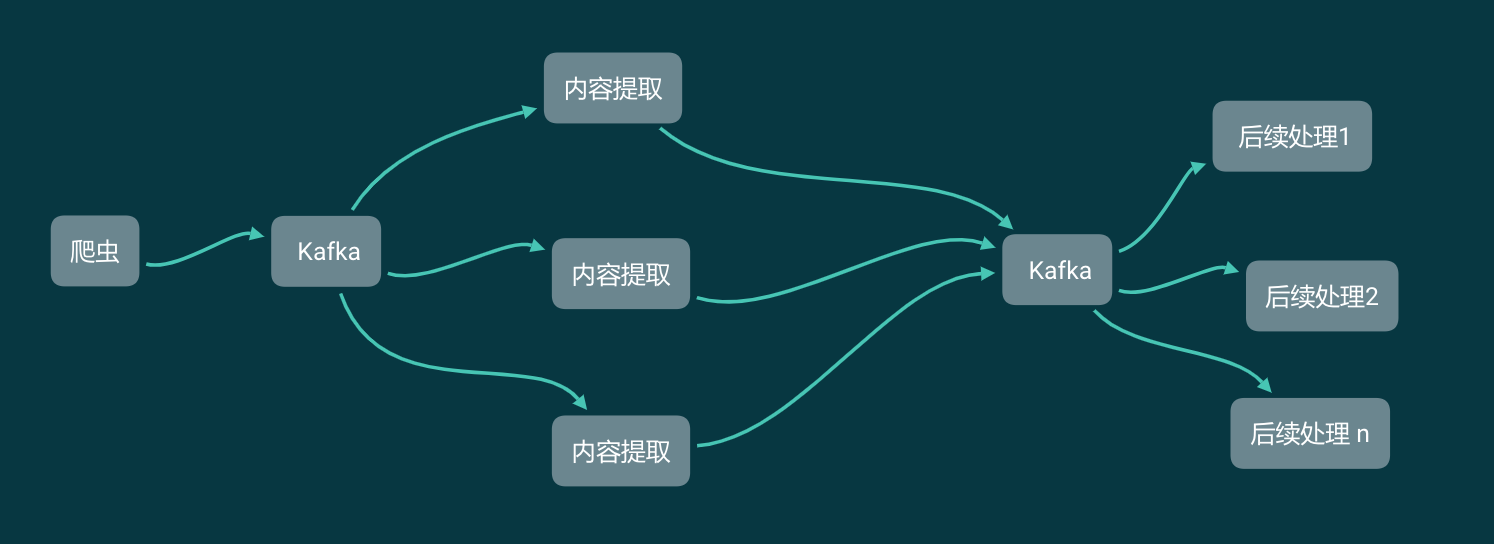
爬虫开发技术好的同学,负责实现绕过反爬虫,获取网站的内容,无论是 HTML 源代码还是接口返回的 JSON。拿到以后,直接塞进 Kafka。
爬虫技术相对一般的同学、实习生,需要做的只是从 Kafka 里面获取数据,不需要关心这个数据是来自于 Scrapy 还是 Selenium。他们要做的只是把这些 HTML 或者 JSON 按照产品要求解析成格式化的数据,然后塞进 Kafka,供后续数据分析的同学继续读取并使用。
如此一来,一个数据小组的工作就分开了,每个人做各自负责的事情,约定好格式,同步开发,互不影响。
为什么是 Kafka 而不是其他
上面描述的功能,实际上有不少 MQ 都能实现。但为什么是 Kafka 而不是其他呢?因为 Kafka 集群的性能非常高,在垃圾电脑上搭建的集群能抗住每秒 10 万并发的数据写入量。而如果选择性能好一些的服务器,每秒 100 万的数据写入也能轻松应对。
总结
这篇文章通过两个例子介绍了 Kafka 在爬虫开发中的作用。作为一个爬虫工程师,作为我的读者。请一定要掌握 Kafka。
下一篇文章,我们来讲讲如何使用 Kafka。比你在网上看到的教程会更简单,更容易懂。

关注本公众号,回复“爬虫与 Kafka”获取本文对应的思维导图原图。
 |
1
wysnylc 2019-12-14 10:22:47 +08:00 如果只写"队列"两个字,你就没法水这么多字了
|
 |
2
lidfather 2019-12-14 10:42:21 +08:00 via Android
。。。
|
 |
3
MemoryCorner 2019-12-14 10:53:13 +08:00
。。。
|
 |
4
neoblackxt 2019-12-14 11:03:19 +08:00
用的什么作图工具
|
 |
5
5G 2019-12-14 11:05:17 +08:00
。。。
|
|
6
5G 2019-12-14 11:05:32 +08:00 @neoblackxt #4 目测 Xmind Zen
|
 |
7
itskingname OP @5G 正解。
|
|
8
itskingname OP @wysnylc 寻常队列可没有这么好的性能
|

 |
10
nobt 2019-12-16 16:35:04 +08:00
。。。
|
 |
11
c8iter 2022-06-26 22:26:58 +08:00
让我来吧,爬虫是犯法的。你这例子举的是微博,也是犯法的。所以你赶紧自首吧。
另外没有爬虫工程师这种岗位。 |